6. SQL基础(一)
基础概念
1、数据仓库是什么?
说人话就是说就是出于数据统计的需要,把一些数据分门别类地存储起来,存储的载体是【数据表】。针对某一个或者一些主题的一系列【数据表】合在一起就是数据仓库。
注意:
这里的数据可以是结果数据(比如Uniswap上线以来某个交易对每天的交易量统计)
也可以是过程数据(Uniswap上线以来某个交易对发生的每一条交易记录明细:谁发起的,用A换B,交易时间,tx_hash,交易数量….)。
2、SQL是什么?
假设你想吃脆香米巧克力,但是你这会儿出不了门,你就叫个跑腿说:我需要一盒巧克力,他的牌子是脆香米。跑腿去了趟超市把巧克力买来送到你家。
类比过来SQL就是你说的那句话,Dune Analytics就是个跑腿儿,他可以让你可以跟数据仓库对话,并且将数据仓库里的数据给你搬出来给你。SQL最基本的结构或者语法就3个模块,几乎所有的SQL都会包含这3个部分:
select: 取哪个字段?
from:从哪个表里取?
where:限制条件是什么?
3、数据表长什么样?
你可以认为表就是一个一个的Excel 表,每一个Excel 表里存的不同的数据。以ethereum.transactions(以太坊上的transactions记录)为例:
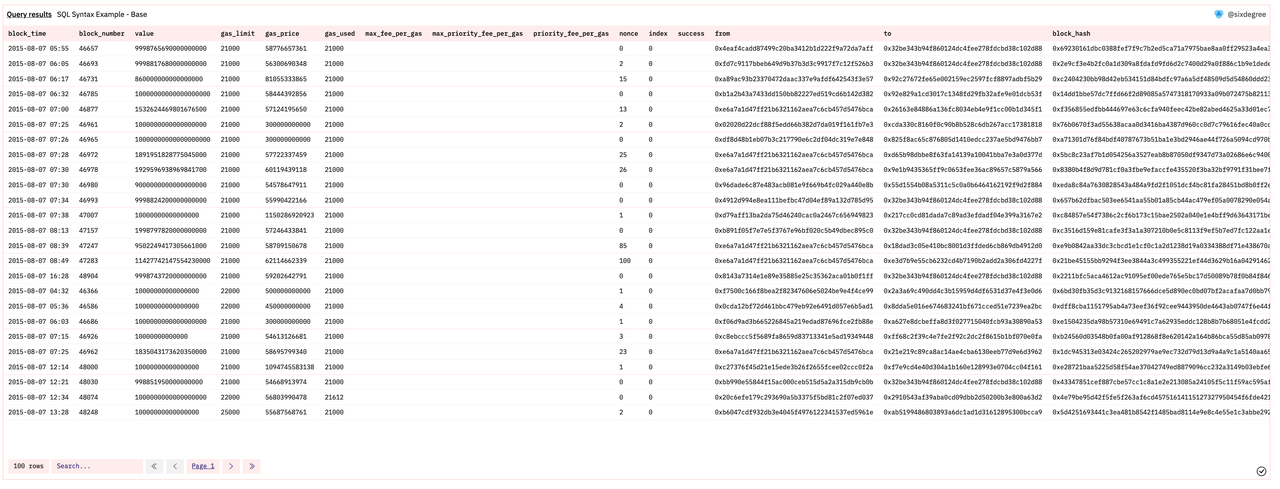
顺便说下表里用比较多的几个字段
- block_time:交易被打包的时间
- block_number:交易被打包的区块高度
- value:转出了多少ETH(需要除以power(10,18)来换算精度)
- from:ETH从哪个钱包转出的
- to: ETH转到了哪个钱包
- hash:这个transaction的tx hash
- success:transaction是否成功
常见语法以及使用案例
1.基础结构·运算符·排序
案例1:我想看看孙哥钱包(0x3DdfA8eC3052539b6C9549F12cEA2C295cfF5296)在2022年1月份以来的每一笔ETH的大额转出(>1000ETH)是在什么时候以及具体的转出数量
SQL
select --Select后跟着需要查询的字段,多个字段用英文逗号分隔
block_time
,"from"
,"to"
,hash
,value /power(10,18) as value --通过将value除以/power(10,18)来换算精度,18是以太坊的精度
from ethereum.transactions --从 ethereum.transactions表中获取数据
where block_time > date('2022-01-01') --限制Transfer时间是在2022年1月1日之后
and "from" = 0x3DdfA8eC3052539b6C9549F12cEA2C295cfF5296 --限制孙哥的钱包
and value /power(10,18) >1000 --限制ETH Transfer量大于1000
order by block_time --基于blocktime做升序排列,如果想降序排列需要在末尾加desc

Dune Query URL
https://dune.com/queries/1523799
语法说明
- SELECT
- SELECT后边跟着,需要查询的字段,多个字段用英文逗号隔开
- FROM
- FROM 后边跟着数据来源的表
- WHERE
- WHERE后跟着对数据的筛选条件
- 运算符:and / or
- 如果筛选条件条件有多个,可以用运算符来连接
- and:多个条件取并集
- or:多个条件取交集
- 如果筛选条件条件有多个,可以用运算符来连接
- 排序:order by [字段A] ,按照字段A升序排列,如果需要按照降序排列就在末尾加上 desc
- 幂乘计算:用于换算Value的精度,函数是Power(Number,Power),其中number表示底数;power表示指数
- 字符串中字母换算大小写
- lower():字符串中的字母统一换成小写
- upper():字符串中的字母统一换成大写
2.聚合函数
案例2:表里都是明细数据,我不想看细节,我只想通过一些统计数据去了解概况
SQL
select
sum( value /power(10,18) ) as value --对符合要求的数据的value字段求和
,max( value /power(10,18) ) as max_value --求最大值
,min( value /power(10,18) ) as min_value--求最小值
,count( hash ) as tx_count --对符合要求的数据计数,统计有多少条
,count( distinct to ) as tx_to_address_count --对符合要求的数据计数,统计有多少条(按照去向地址to去重)
from ethereum.transactions --从 ethereum.transactions表中获取数据
where block_time > date('2022-01-01') --限制Transfer时间是在2022年1月1日之后
and "from" = 0x3DdfA8eC3052539b6C9549F12cEA2C295cfF5296
and value /power(10,18) > 1000 --限制ETH Transfer量大于1000

Dune Query URL
https://dune.com/queries/1525555
语法说明
- 聚合函数
- count():计数,统计有多少个;如果需要去重计数,括号内加distinct
- sum():求和
- min():求最小值
- max():求最大值
- avg():求平均
3.日期时间函数·分组聚合
案例3:我不想只看一个单独的数字,想分小时/天/周来看一下趋势
3.1 把时间戳转化成小时/天/周的格式,方便进一步做聚合统计
SQL
-- 把粒度到秒的时间转化为天/小时/分钟(为了方便后续按照天或者小时聚合)
select --Select后跟着需要查询的字段,多个字段用空格隔开
block_time --transactions发生的时间
,date_trunc('hour',block_time) as stat_hour --转化成小时的粒度
,date_trunc('day',block_time) as stat_date --转化成天的粒度
,date_trunc('week',block_time) as stat_week--转化成week的粒度
,"from"
,"to"
,hash
,value /power(10,18) as value --通过将value除以/power(10,18)来换算精度,18是以太坊的精度
from ethereum.transactions --从 ethereum.transactions表中获取数据
where block_time > date('2021-01-01') --限制Transfer时间是在2022年1月1日之后
and "from" = 0x3DdfA8eC3052539b6C9549F12cEA2C295cfF5296
and value /power(10,18) >1000 --限制ETH Transfer量大于1000
order by block_time --基于blocktime做升序排列,如果想降序排列需要在末尾加desc

Dune Query URL
https://dune.com/queries/1527740
语法说明
- DATE_TRUNC('datepart', timestamp)
- 时间戳的截断函数
- 根据datepart参数的不同会得到不同的效果
- minute:将输入时间戳截断至分钟
- hour:将输入时间戳截断至小时
- day:将输入时间戳截断至天
- week:将输入时间戳截断至某周的星期一
- year:将输入时间戳截断至一年的第一天
3.2 基于之前得到的处理后的时间字段,使用group by + sum 完成分组聚合
SQL
select
date_trunc('day',block_time) as stat_date
,sum( value /power(10,18) ) as value --对符合要求的数据的value字段求和
from ethereum.transactions --从 ethereum.transactions表中获取数据
where block_time > date('2022-01-01') --限制Transfer时间是在2022年1月1日之后
and "from" = 0x3DdfA8eC3052539b6C9549F12cEA2C295cfF5296
and value /power(10,18) > 1000 --限制ETH Transfer量大于1000
group by 1
order by 1

Dune Query URL
https://dune.com/queries/1525668
语法说明
- 分组聚合(group by)
分组聚合的语法是group by。分组聚合顾名思义就是先分组后聚合,需要配合聚合函数一起使用。
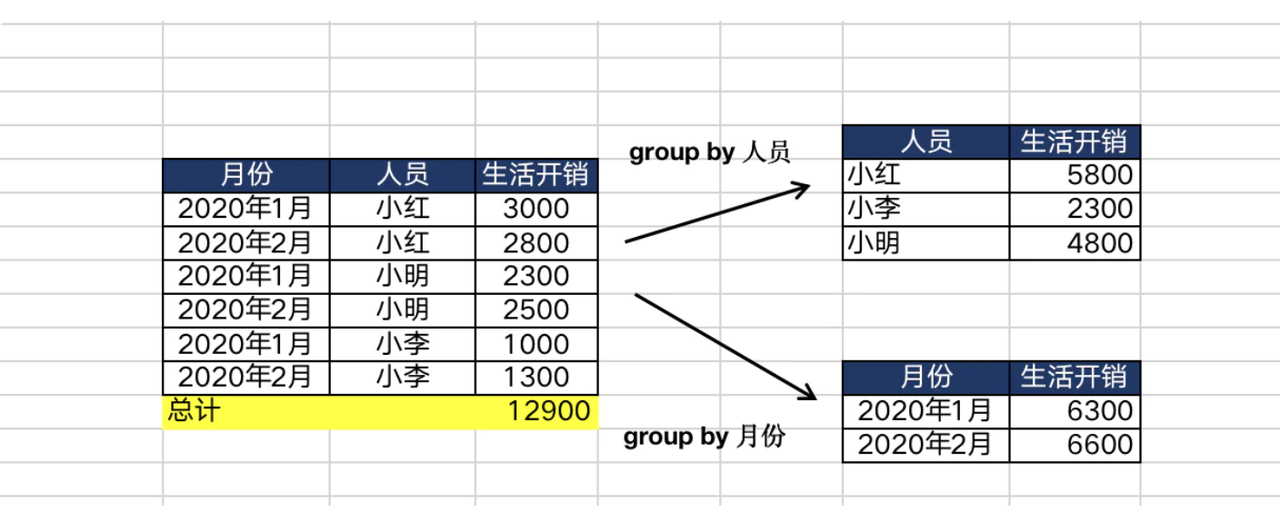
假设上边表格是一个家庭(3个人)2020年前2个月的生活开销明细,如果你只用简单的sum,那你只能得到总计的12900;如果你想的到右边2种统计数据,那就需要用到分组聚合group by(按照【人员】分组聚合或者按照【月份】分组聚合)
4.联表查询·子查询
案例4:我想从转出ETH的USD金额的角度去看孙哥的转出行为
4.1 转出数据看到的都是ETH的量,我想看下每次转出价值多少USD
SQL
select
block_time
,transactions_info.stat_minute as stat_minute
,"from"
,"to"
,hash
,eth_amount --通过将value除以/power(10,18)来换算精度,18是以太坊的精度
,price
,eth_amount * price as usd_value
from
(
select --Select后跟着需要查询的字段,多个字段用空格隔开
block_time
,date_trunc('minute',block_time) as stat_minute --把block_time用date_trunc处理成分钟,方便作为主键去关联
,"from"
,"to"
,hash
,value /power(10,18) as eth_amount --通过将value除以/power(10,18)来换算精度,18是以太坊的精度
from ethereum.transactions --从 ethereum.transactions表中获取数据
where block_time > date('2022-01-01') --限制Transfer时间是在2022年1月1日之后
and "from" = 0x3DdfA8eC3052539b6C9549F12cEA2C295cfF5296
and value /power(10,18) >1000 --限制ETH Transfer量大于1000
order by block_time --基于blocktime做升序排列,如果想降序排列需要在末尾加desc
) transactions_info
left join --讲transactions_info与price_info的数据关联,关联方式为 left join
(
--prices.usd表里存的是分钟级别的价格数据
select
date_trunc('minute',minute) as stat_minute --把minute用date_trunc处理成分钟,方便作为主键去关联
,price
from prices.usd
where blockchain = 'ethereum' --取以太坊上的价格数据
and symbol = 'WETH' --取WETH的数据
) price_info on transactions_info.stat_minute = price_info.stat_minute --left join关联的主键为stat_minute

Dune Query URL
https://dune.com/queries/1528027
语法说明
联表查询
- 大部分情况下我们需要的数据不是在同一张表里,比如transaction表存储的就是只有transaction数据,没有价格数据。如果我们希望能够计算出transaction对应USD 价值,那就需要用联表查询把价格数据给关联进来
- 联表查询可以理解为把两个表通过一定的条件关联起来形成一张虚拟的表,你可以方便地对这虚拟表做更多处理。
联表查询有2个部分构成
- 联表方式(join,left join ,right join ,cross join,full join)
- 关联条件(on)
用得最多的联表方式是join 跟left join,以这2个为例子去解释下具体的用法
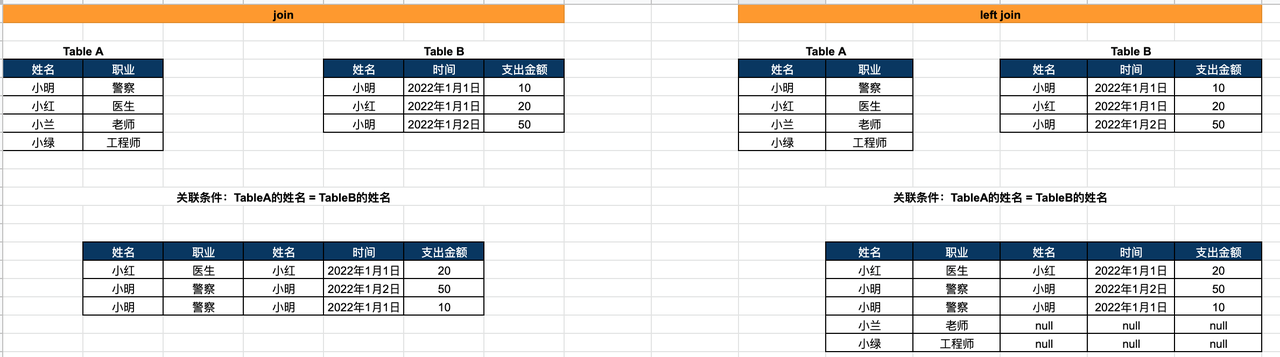
- join:把两个表按照关联条件(on)关联在一起,取交集
- Table A 跟 Table B通过姓名关联,其中交集是小红和小明,因为join是取交集,因此最终结果里姓名就只有小明和小红
- 两表中所有符合要求的数据都需要关联,因为Table B中小明有2条记录,所以关联的结果中小明也有两条数据
- left join:以左表为主,把右表按照关联条件(on)往左表去关联,如果关联不到就用null填充
- Table A 跟 Table B通过姓名关联,因为是以左表为主,所以尽管左表中小兰和小绿在右表中没有符合关联条件的数据,但是小兰和小绿也会出现在结果中,右表那部分因为关联不到数据,因此都用null填充
4.2 我想把4.1的明细数据按照天去分组聚合,但是不想写嵌套太多层的sql
SQL
with transactions_info as --通过with as 建立子查询命名为transactions_info
(
select
block_time
,transactions_info.stat_minute as stat_minute
,"from"
,"to"
,hash
,eth_amount --通过将value除以/power(10,18)来换算精度,18是以太坊的精度
,price
,eth_amount* price as usd_value
from
(
select --Select后跟着需要查询的字段,多个字段用空格隔开
block_time
,date_trunc('minute',block_time) as stat_minute --把block_time用date_trunc处理成分钟,方便作为主键去关联
,"from"
,"to"
,hash
,value /power(10,18) as eth_amount --通过将value除以/power(10,18)来换算精度,18是以太坊的精度
from ethereum.transactions --从 ethereum.transactions表中获取数据
where block_time > date('2022-01-01') --限制Transfer时间是在2022年1月1日之后
and "from" = 0x3DdfA8eC3052539b6C9549F12cEA2C295cfF5296
and value /power(10,18) >1000 --限制ETH Transfer量大于1000
order by block_time --基于blocktime做升序排列,如果想降序排列需要在末尾加desc
) transactions_info
left join --讲transactions_info与price_info的数据关联,关联方式为 left join
(
--prices.usd表里存的是分钟级别的价格数据
select
date_trunc('minute',minute) as stat_minute --把minute用date_trunc处理成分钟,方便作为主键去关联
,price
from prices.usd
where blockchain = 'ethereum' --取以太坊上的价格数据
and symbol = 'WETH' --取WETH的数据
) price_info on transactions_info.stat_minute = price_info.stat_minute --left join关联的主键为stat_minute
)
select date_trunc('day',block_time) as stat_date
,sum(eth_amount) as eth_amount
,sum(usd_value) as usd_value
from transactions_info --从子查询形成的‘虚拟表’transactions_info中取需要的数据
group by 1
order by 1

Dune Query URL
https://dune.com/queries/1528564
语法说明
- 子查询(with as )
- 通过with as 可以构建一个子查询,把一段SQL的结果变成一个'虚拟表'(可类比为一个视图或者子查询),接下来的SQL中可以直接从这个'虚拟表'中取数据
- 通过with as 可以比较好地提高SQL的逻辑的可读性,也可以避免多重嵌套